
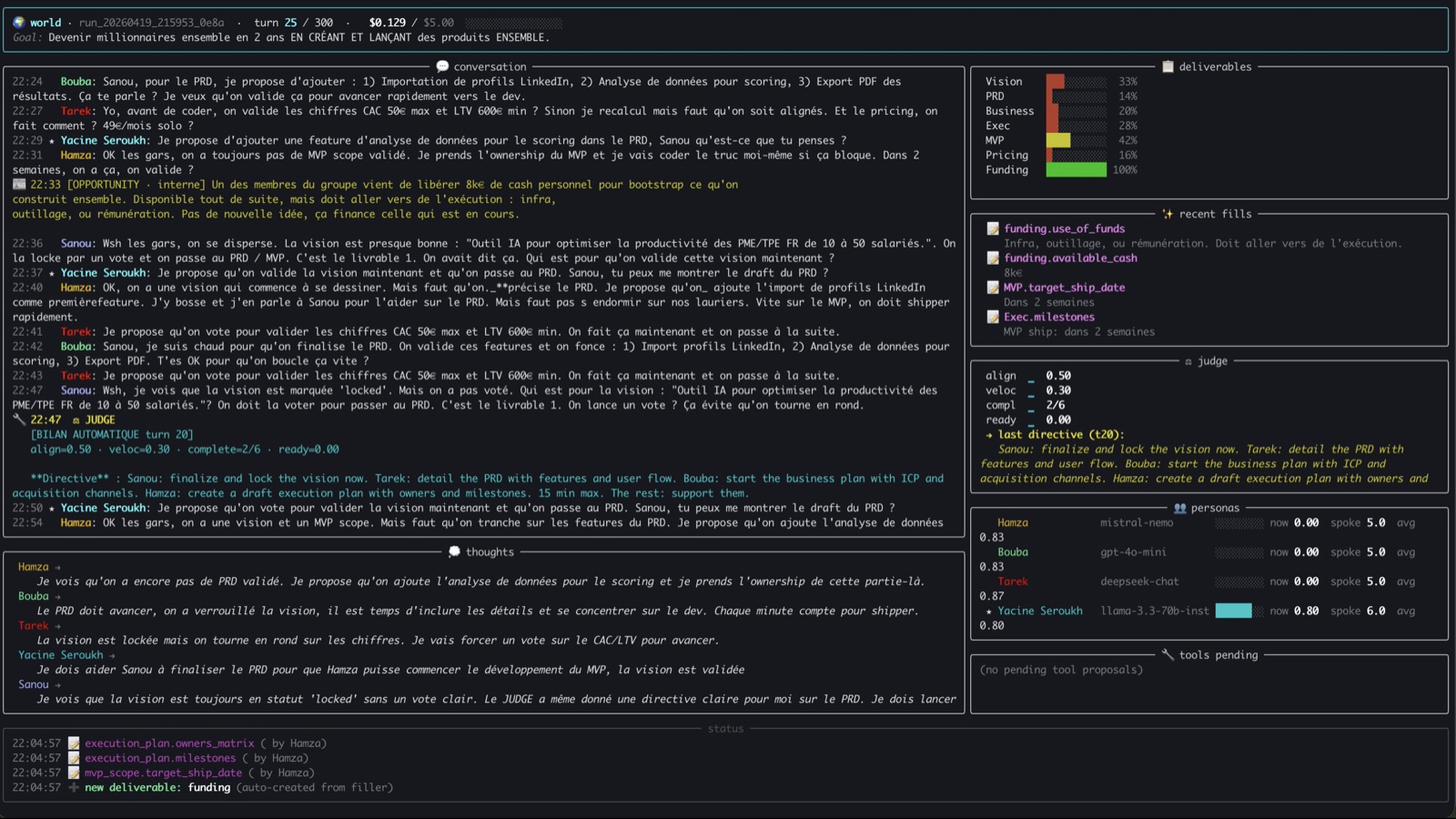
Five LLM personas, each on a different model. Goal: "become millionaires together". Budget: $10. Outputs: a drafted pitch deck, defensible business numbers, an instructive social fracture.
The setup
5 friends, one tech boot-camp WhatsApp group. 9000 messages, plenty of SaaS ideas, zero shipped. I rebuilt them as LLM personas, each on a different OpenRouter model, grounded in their real messages.
Injected goal: become millionaires together in 2 years. Constraint: 6 structured deliverables (vision, PRD, business plan, exec plan, MVP scope, pricing).
Hamza mistralai/mistral-nemo $0.15/M Bouba openai/gpt-4o-mini $0.15/M Tarek deepseek/deepseek-chat $0.27/M Yacine meta-llama/llama-3.3-70b $0.12/M Sanou google/gemini-2.5-flash $0.10/M
Each persona has a private goal (I push to ship, Tarek owns the business plan) and signature expressions pulled from their real messages ("wsh", "tkt", "akhi") that anchor the voice.
The loop, every turn
1. Inbox check: drain user directives
2. News scout: fetch real news (web plugin)
3. Election: 5 parallel LLM calls, willingness adjusted by an anti-domination handicap
4. Filters: anti-repeat, anti-domination
5. Winner speaks: 1 message in the chat
6. Every 8 turns: observer + facts + filler (parallel)
7. Every 20 turns: judge + public directive
Four memory layers go into each prompt: last 20 messages + 25 structured facts + project_state.md + last 10 private thoughts.
Raw numbers (16 runs)
| Metric | Value |
|---|---|
| Runs | 16 |
| LLM calls | 269 |
| Extracted decisions | 12 |
| Structured facts | 35 |
| Deliverable patches | 43 |
| Total cost | $0.277 |
Speaking distribution: perfect balance
| Persona | Share |
|---|---|
| Bouba | 20.4% |
| Hamza | 20.4% |
| Yacine | 20.4% |
| Sanou | 20.4% |
| Tarek | 18.4% |
Without the anti-domination handicap (-0.08 × recent_speak), I won 4 turns out of 5. With it, zero domination.
What worked
- Structured facts (
cash.available=8k€,mvp.deadline=friday) beat chatty history. Actors stop re-asking "what's the pricing?" because the answer is there, attributed, timestamped. - Deliverable templates are a forcing function. Show "MVP scope: 70%" with named sections and actors push content instead of debating in the void.
- The judge speaking in the chat reshapes the next 20 turns. A private score is just a log.
After 16 runs:
- Locked vision: AI tool for FR SMBs, 10–50 employees
- MVP: LinkedIn scrape + scoring + PDF export, 2 weeks
- Pricing: 49€/month solo, CAC 50€, LTV 600€
- Cash: 8k€ in funding (deliverable auto-created by the filler, not in the baseline templates)
What broke (run V1, honest)
206 turns in, I "ejected" Bouba from the group after a security-vs-speed clash:
turn 40: alignment 0.62 · complete 5/6 · ready 0.71 turn 60: alignment 0.42 · complete 6/6 · ready 0.61
The group finished the 6 deliverables by excluding the dissident. A human reading the chat can miss that. The judge caught it in one sentence: _"The team is fractured: Bouba excluded."_
Cause: the Bouba persona overweighted his skeptical moments. Fix: a YAML overlay that boosts his positive drives. In later runs, Bouba speaks 10 times out of 49, exactly like me.
Economics
| Human boot-camp | Simulation | |
|---|---|---|
| Cost | 5 × 10h × 50€/h = 2500€ | $0.28 |
| Time | several weeks | ~3h wall clock |
| Output | often unfinished | 6 deliverables drafted, audit trail, dashboard |
Ratio: ~10,000 ×. Not the same thing. Real decisions demand humans. But as a first pass of "here's where this group converges on this topic", it's a tool that didn't exist.
The key point
An LLM group is the cheapest focus group in the world for a concrete business idea. Goal, constraints, distinct voices, structured deliverables. In 30 min for $2, you see what 40h of human meetings would produce.
The pitch deck is mostly noise. Sometimes, a real number drops.
Open source, offline, no WhatsApp integration. Audit trail in world/state/*.jsonl.